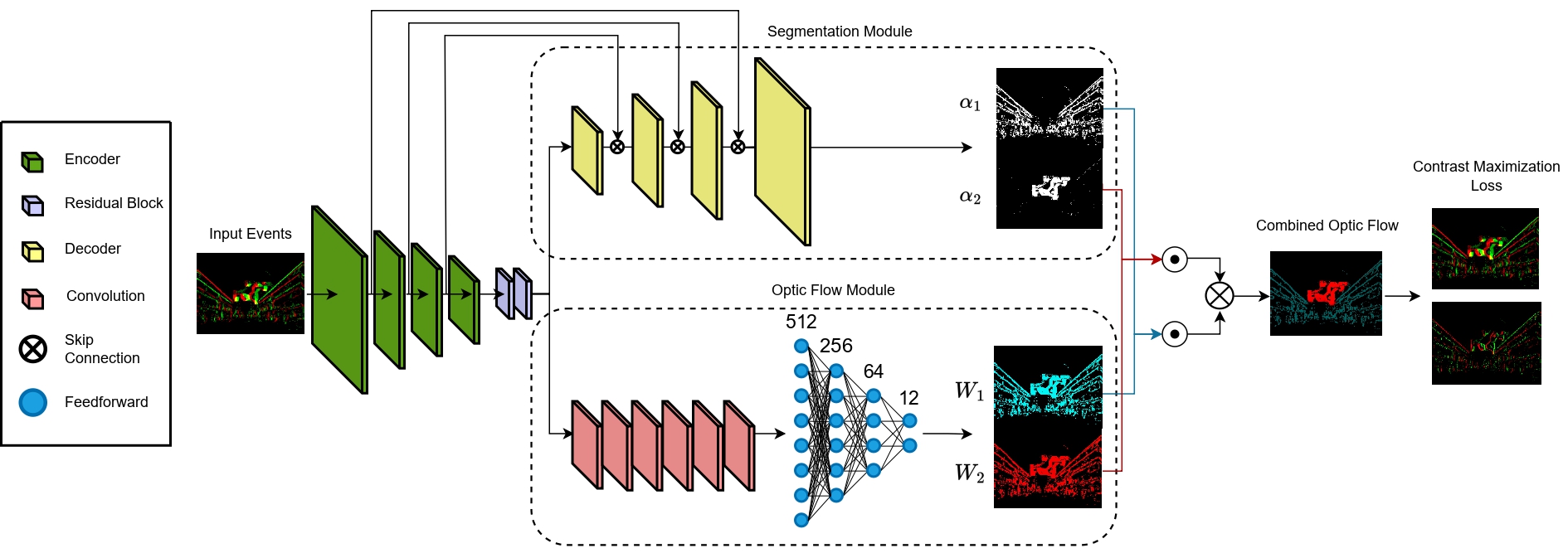
Event cameras are novel bio-inspired sensors that capture motion dynamics with much higher temporal resolution than traditional cameras, since pixels react asynchronously to brightness changes. They are therefore better suited for tasks involving motion such as motion segmentation. However, training event-based networks still represents a difficult challenge, as obtaining ground truth is very expensive, error-prone and limited in frequency. In this article, we introduce EV-LayerSegNet, a self-supervised CNN for event-based motion segmentation. Inspired by a layered representation of the scene dynamics, we show that it is possible to learn affine optical flow and segmentation masks separately, and use them to deblur the input events. The deblurring quality is then measured and used as self-supervised learning loss. We train and test the network on a simulated dataset with only affine motion, achieving IoU and detection rate up to 71% and 87% respectively.